BERT has revolutionized the field of natural language processing (NLP) with its groundbreaking ability to understand language in a deeply contextual and nuanced way.
Developed by Google, BERT (Bidirectional Encoder Representations from Transformers) is one of the most influential language models in modern NLP. It significantly enhances how machines understand, interpret, and interact with human language—from search engines and chatbots to text classification and question-answering systems.
But what exactly is BERT, and why is it such a game-changer for artificial intelligence? Let’s dive into what makes this model so powerful and explore how it works.

What Is BERT?
At its core, BERT is a deep learning model based on the Transformer architecture, introduced by Google in 2018. What sets BERT apart is its ability to understand the context of a word by looking at both the words before and after it—this bidirectional context is key to its superior performance.
While many earlier models processed language in a single direction (usually left to right), BERT’s bidirectional nature allows it to grasp the full meaning of a sentence more effectively, leading to more accurate understanding in NLP tasks.
How BERT Works: The Technology Behind the Model
1. Transformer Architecture with Self-Attention
BERT is built on the Transformer model, specifically its encoder component. Through a mechanism called self-attention, BERT processes all words in a sentence simultaneously and evaluates the relationship between them. This enables a deeper understanding of meaning and context.
2. Pre-training and Fine-tuning
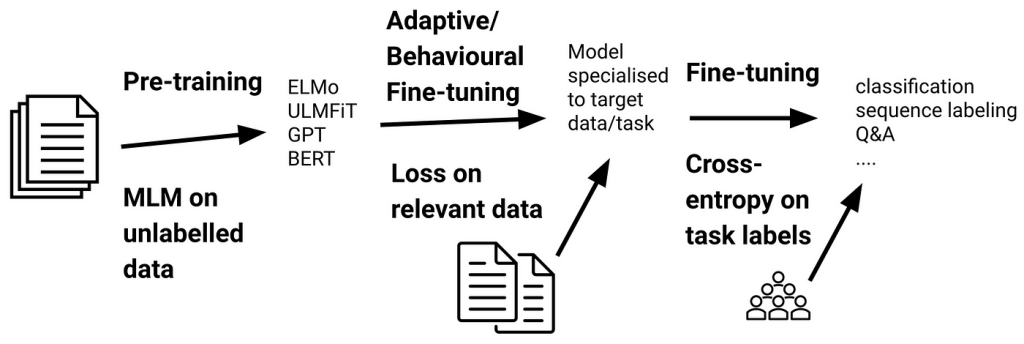
BERT is trained in two main phases:
- Pre-training: BERT was initially trained on massive datasets, including the entire English Wikipedia (~2.5 billion words) and the BooksCorpus dataset (~800 million words). This phase helps the model build a broad understanding of language.
- Fine-tuning: Once pre-trained, BERT can be fine-tuned for specific tasks—such as sentiment analysis, entity recognition, or answering questions—using relatively small datasets. Google uses transfer learning here, which significantly reduces training time and cost while boosting performance.
3. Core Training Objectives
BERT uses two innovative techniques during pre-training:
- Masked Language Modeling (MLM): Random words in a sentence are hidden, and the model must predict them using the surrounding context. This teaches BERT to understand meaning in both directions.
- Next Sentence Prediction (NSP): This task involves determining whether one sentence logically follows another. NSP helps BERT grasp the relationship between sentences—vital for many NLP applications.
The Architecture of BERT
BERT is essentially a multi-layered encoder stack from the Transformer model. Unlike the original Transformer, BERT doesn’t use the decoder—only the encoder, since its primary job is understanding language rather than generating it.

There are two primary versions of BERT:
- BERTBASE: 12 encoder layers, 12 attention heads, 768 hidden units, and about 110 million parameters.
- BERTLARGE: 24 encoder layers, 16 attention heads, 1024 hidden units, totaling 340 million parameters.
Compared to the original Transformer (which had 6 layers and fewer attention heads), both BERTBASE and BERTLARGE are significantly more powerful, enabling deeper language understanding.
BERT vs. GPT: What’s the Difference?
While BERT and GPT (Generative Pre-trained Transformer) are both based on the Transformer architecture, they differ fundamentally in how they work and what they’re used for.

| Feature | BERT | GPT |
|---|---|---|
| Architecture | Bidirectional encoder, uses Masked Language Modeling (MLM) | Unidirectional decoder, uses autoregressive language modeling |
| Training Objective | Predict masked words and assess sentence relationships (NSP) | Predict the next word based on preceding context |
| Context Understanding | Strong at understanding sentence meaning and inter-word relationships | Excels at generating coherent, contextually appropriate text |
| Best Used For | Text classification, named entity recognition, question answering | Text generation, chatbots, content creation, summarization |
| Adaptability | Fine-tuned on labeled datasets for specific tasks | Few-shot and zero-shot learning capabilities for broader flexibility |
| Text Processing Direction | Bidirectional (left-to-right and right-to-left) | Unidirectional (typically left-to-right) |
| Real-World Applications | Google Search, Gmail, Google Docs, voice assistants | Code generation, writing tools, chat systems, legal document drafting |
| Performance Benchmarks | 80.4% GLUE score, 93.3% accuracy on SQuAD | 76.2% accuracy on LAMBADA (zero-shot), 64.3% on TriviaQA |
The Advantages and Applications of BERT in Natural Language Processing
BERT (Bidirectional Encoder Representations from Transformers) has become a game-changer in the field of natural language processing (NLP). Developed by Google, this pre-trained language model is known for its ability to deeply understand the context of language and deliver impressive performance across a wide range of NLP tasks. Below, we’ll explore the key benefits, real-world applications, challenges, and popular variations of BERT.
Key Benefits of BERT
1. Text Representation and Classification
BERT excels at generating powerful vector representations of text, which can be leveraged for various downstream tasks. Thanks to its bidirectional multi-layer Transformer encoder, it understands sentence structures and contextual nuances effectively. As a result, it’s widely used in text classification, named entity recognition, and sentiment analysis.
2. Labeling Unlabeled Data
Data scientists often rely on BERT to assist in labeling previously unlabeled data. By fine-tuning a pre-trained BERT model on a labeled dataset, it can predict labels for new data. For example, BERT can be combined with a classification layer to identify sentiment in user reviews. These predicted labels can then be used to train a smaller, specialized model for deployment in business workflows.
3. Ranking and Recommendation
BERT’s contextual understanding enhances search ranking and recommendation systems, particularly in e-commerce and content platforms. By capturing relationships between words more accurately, it improves the relevance of search results. Companies like Amazon have adopted BERT to refine product recommendations, helping users find what they need more quickly and accurately.
4. Computational Efficiency
Compared to newer NLP models like GPT-4 or PaLM 2, which require complex multi-GPU setups, BERT can be fine-tuned using just a single GPU. Lightweight variants like DistilBERT or BERT-Base are even capable of running on mobile devices or embedded systems, making them accessible for a wide range of applications.
5. Faster Development Cycles
Since BERT comes pre-trained on massive corpora, developers only need to fine-tune it for specific use cases, significantly speeding up the development and deployment process. Some variations are optimized for smaller size and faster performance while maintaining high accuracy, allowing organizations to integrate BERT into real-world systems quickly and cost-effectively.
Real-World Applications of BERT
BERT’s versatility makes it valuable across industries—from office tools and customer support to healthcare and legal services. Here are some of the most common applications:
- Question Answering: BERT powers customer service bots and search engines by interpreting the context of questions and providing accurate answers.
- Sentiment Analysis: It detects user sentiment in reviews, feedback, and social media posts by analyzing the emotional tone of text.
- Text Generation: BERT can generate coherent and contextually relevant content from simple prompts, making it useful for drafting emails, reports, or chatbot replies.
- Summarization: In specialized domains like healthcare and law, BERT can summarize lengthy documents, helping users digest critical information quickly.
- Language Translation: With multilingual training, BERT can assist in translating input for global users.
- Task Automation: Businesses use BERT to automate repetitive tasks like sending messages or managing communications, saving time and increasing productivity.
- Named Entity Recognition (NER): BERT identifies specific names, locations, organizations, and other entities in text, supporting information extraction and intelligent data management.
- Text Classification: It categorizes documents by topic or type—such as distinguishing spam from legitimate emails—streamlining content filtering.
Challenges and Limitations
Despite its strengths, BERT is not without its shortcomings:
- Limited Deep Context Understanding: While BERT generates coherent text and understands general context, it may struggle with deeper meanings, ambiguous phrases, or nuanced intent.
- Lack of Logical Reasoning: BERT doesn’t possess true reasoning capabilities and cannot draw inferences the way humans do, especially when information is incomplete or implied.
- Creativity Constraints: Although BERT can mimic human-like writing, it lacks originality and can’t generate novel ideas or concepts.
- Bias and Fairness Concerns: BERT’s performance may reflect biases in its training data, which can lead to skewed or unfair outcomes.
- High Resource Demand and Limited Flexibility: While lighter versions exist, standard BERT models are resource-intensive and may need retraining when applied to new domains, reducing flexibility and scalability.
Popular Variants of BERT
Because BERT is open-source, many organizations and research teams have built on it to create specialized versions:
- PatentBERT: Fine-tuned for patent classification tasks.
- DocBERT: Optimized for document classification.
- BioBERT: Tailored for biomedical text mining and medical literature.
- VideoBERT: A multi-modal model combining language and video data for unsupervised learning from platforms like YouTube.
- SciBERT: Adapted for scientific publications.
- G-BERT: Uses graph neural networks and medical codes to make healthcare recommendations.
- TinyBERT (Huawei): A distilled version of BERT that’s 7.5x smaller and 9.4x faster than BERT-Base.
- DistilBERT (Hugging Face): A compact, cost-efficient version trained via distillation from BERT.
- ALBERT: A lightweight version designed to reduce memory usage and speed up training.
- SpanBERT: Improves BERT’s span-level prediction capabilities.
- RoBERTa: Trained on more data and for longer durations than the original BERT, enhancing performance.
- ELECTRA: Produces higher-quality text representations through an alternative training method.
Final Thoughts
As highlighted by MiniToolAI, BERT has solidified its place as one of the most advanced and efficient models in natural language processing. Its ability to understand bidirectional context allows it to excel in tasks ranging from search and sentiment analysis to customer support and text summarization. With applications spanning healthcare, law, education, and more, BERT continues to push the boundaries of what AI can achieve in language understanding. By grasping how BERT works and where it thrives, individuals and organizations can fully harness its potential to enhance accuracy, efficiency, and impact across various NLP applications.
")


