In the world of artificial intelligence, the Transformer has emerged as a game-changing neural network architecture that revolutionized how machines process natural language. Thanks to its powerful self-attention mechanism, the Transformer enables models to understand and generate human language with remarkable accuracy. It’s the backbone of many advanced AI applications today—including ChatGPT and Google’s Gemini. Let’s dive into what makes the Transformer so special, why it’s essential, and how it’s applied in real-world scenarios.

What Is a Transformer?
A Transformer is a deep learning architecture designed specifically to handle sequential data, especially natural language. First introduced in a 2017 research paper titled “Attention is All You Need” by Vaswani et al., this model has since become the foundation of virtually every major advancement in natural language processing (NLP).
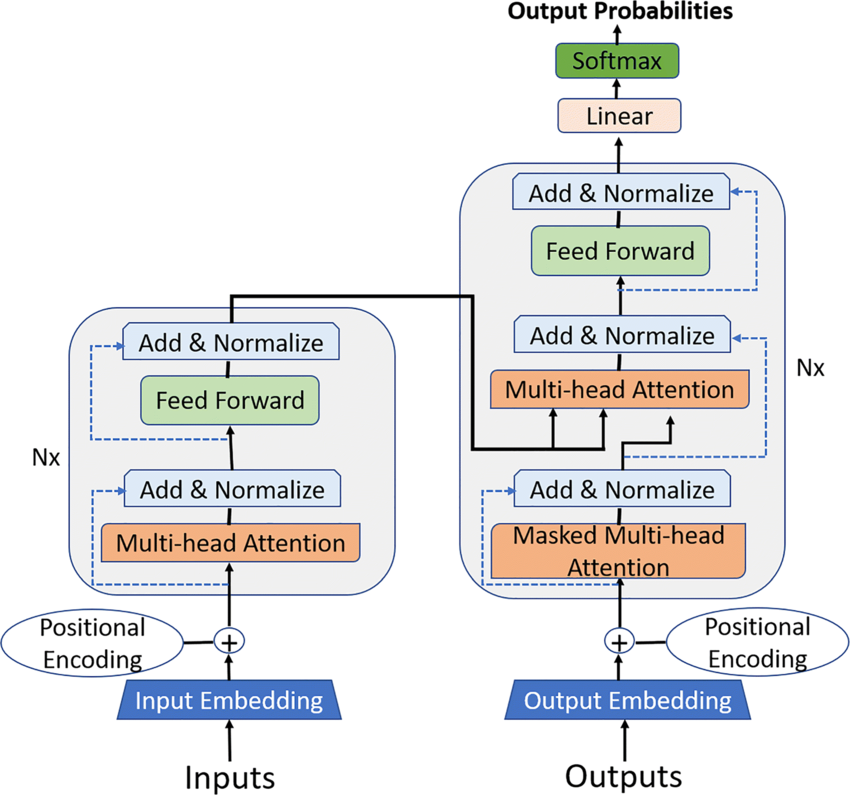
Unlike previous models that relied heavily on recurrence or convolution, the Transformer architecture is built entirely on attention mechanisms—particularly self-attention. It consists of two main components: encoders, which interpret input data, and decoders, which generate output based on that understanding. The innovation lies in how these components interact through attention layers, allowing the model to weigh the importance of each word relative to the others in a sentence.
Why Transformers Matter
What sets Transformers apart is the self-attention mechanism, which enables the model to assess relationships between all parts of the input data simultaneously. This contrasts with earlier models like RNNs (Recurrent Neural Networks) or CNNs (Convolutional Neural Networks), which process information sequentially or in fixed-size chunks, limiting their ability to capture long-range dependencies in text.
Self-attention—especially in its multi-head variant—lets the model focus on different parts of a sequence from multiple perspectives at once. This flexibility leads to stronger contextual understanding and more coherent outputs, making Transformers more effective for tasks like translation, summarization, and sentiment analysis.
Limitations of Pre-Transformer NLP Models
Before the rise of Transformer models, NLP tasks were predominantly handled by RNNs and their more advanced variants like LSTMs (Long Short-Term Memory) and GRUs (Gated Recurrent Units). While these architectures brought notable improvements, they also came with several key limitations:
- Struggles with Long-Term Dependencies: RNNs often failed to retain important information over long text sequences. LSTMs and GRUs tried to mitigate this, but the problem wasn’t fully solved.
- Lack of Parallelism: These models processed sequences one step at a time, making it difficult to scale training on modern hardware like GPUs.
- Inefficient Performance: Their sequential nature limited how effectively they could take advantage of parallel computing resources, resulting in longer training times.
Transformers addressed all these issues by removing recurrence altogether. Instead, they apply attention across the entire input simultaneously, enabling both faster training and better performance.
Key Advantages of Transformer Models
Here’s why Transformer-based models have become the new standard in NLP:
- Parallel Processing: Transformers process input sequences all at once rather than one token at a time, which significantly speeds up training.
- Contextual Understanding: The self-attention mechanism enables the model to understand the full context of a sentence, even when related words are far apart.
- Scalability and Efficiency: Transformers are highly optimized for modern hardware, making it easier to train large-scale models like BERT, GPT-3, and beyond.
Real-World Impact
Transformers have laid the groundwork for many state-of-the-art AI systems. ChatGPT, Gemini, BERT, and other cutting-edge models are all built upon this architecture. Whether it’s chatbots, machine translation, content summarization, or search engine optimization, Transformer models are at the heart of the current AI revolution.
How Transformers Work: An Intuitive Overview
Transformers are the backbone of modern AI systems, particularly in natural language processing (NLP) and beyond. To understand how they function, let’s break down their core components and processing steps:
1. Input Embedding
Every input sequence (like a sentence) is first converted into numerical vectors known as embeddings. Each word or token is mapped to a fixed-size vector that captures semantic meaning based on prior training.
2. Positional Encoding
Unlike recurrent networks, Transformers don’t process data in sequential order. To provide a sense of word position within the sequence, positional encoding is added to the embeddings. This allows the model to capture the order of tokens.
3. Encoder Stack
The modified input is then passed through a series of encoder layers, each composed of two key components:
- Multi-head self-attention, which allows the model to focus on different parts of the sequence simultaneously, capturing contextual relationships.
- Feed-forward neural networks, applied independently to each position, further processing the attention outputs.
4. Decoder Stack
The decoder, responsible for generating output sequences (e.g., translated text), also consists of multiple layers. Each decoder layer includes:
- A masked multi-head self-attention mechanism to ensure predictions depend only on earlier outputs.
- An encoder-decoder attention layer that helps the decoder focus on relevant input parts.
- A feed-forward neural network to finalize the token output at each step.
This encoder-decoder architecture enables Transformers to map input sequences to outputs effectively, making them ideal for machine translation, summarization, and question-answering systems.
Key Challenges Facing Transformer Models
Despite their capabilities, Transformer models also come with several significant challenges:
High Computational Cost
Training large models like GPT-3 or GPT-4 is extremely resource-intensive. For instance, GPT-3 with 175 billion parameters reportedly cost around $12 million just in compute expenses. This makes large-scale Transformer development viable mainly for tech giants.
Environmental Impact
Studies have shown that training massive Transformer models can emit carbon equivalent to the lifetime emissions of several cars, raising concerns about sustainability.
Data Requirements
Transformers typically require massive, high-quality labeled datasets. For example, GPT-3 was trained on over 570GB of diverse text data. Even fine-tuning for domain-specific tasks can demand hundreds of thousands of labeled examples, which poses a challenge for smaller organizations.
Real-World Applications of Transformers
Transformers are revolutionizing more than just NLP—they’re making an impact across a wide range of industries.
In Natural Language Processing (NLP)

- Text Generation: Transformer-based models like GPT have significantly advanced machine-generated writing, contributing to the rise of generative AI.
- Machine Translation: Tools like Google Translate and DeepL leverage Transformers to produce more accurate and natural translations.
- Text Summarization: Models like Pegasus can condense long documents into concise summaries, saving time and effort.
- Sentiment Analysis: Transformers help businesses analyze public sentiment through product reviews and social media, often using tools like TextBlob or VADER.
- Named Entity Recognition (NER): Systems like spaCy and Flair use Transformers to identify names, places, and other entities in text automatically.
- Question Answering: Pre-trained models from libraries like Hugging Face’s Transformers can understand a question and extract accurate answers from context.
- Language Modeling: Models like BERT and XLNet enhance machines’ ability to understand and generate human-like language.
- Text Classification: Transformer models can categorize text into classes such as spam/non-spam, news topics, and more.
- Multilingual Transfer Learning: Transformers can learn from resource-rich languages and transfer that knowledge to underrepresented ones.
- Dialogue Systems: They power intelligent chatbots and virtual assistants capable of engaging in natural, contextual conversation.
In Computer Vision
- Image Captioning: Transformers generate descriptive captions for images, aiding accessibility and search engines.
- Object Detection: Integrating Transformers boosts the performance of object detectors like YOLO and Faster R-CNN.
- Image Classification: Models such as Vision Transformers (ViTs) excel at tagging images with the correct labels.
- Semantic Segmentation: Tools like MMSegmentation use Transformers to separate an image into meaningful parts, useful in medical imaging and self-driving.
- Video Analysis: Transformers can analyze video frames to detect actions, generate captions, and more, as seen in projects like VidTransformer.
Try Image Description Generator for free: minitoolai.com/Image-Description-Generator/
In Other Domains
- Speech Recognition: Services like Google Speech-to-Text now utilize Transformers to transcribe audio more accurately across accents and languages.
- Time Series Forecasting: Transformers help in predicting trends in finance, weather, and inventory by learning patterns over time.
- Bioinformatics: Transformers are revolutionizing drug discovery and protein structure prediction through models like ESM and ProtTrans.
- Recommendation Systems: Platforms like Netflix and Spotify leverage Transformers to deliver highly personalized content recommendations.
- Anomaly Detection: Transformers can identify irregular patterns in systems or transactions, useful in fraud detection and system monitoring.
- Robotics: Transformers enable robots to better interpret and respond to their environments using reinforcement learning frameworks like RLBench.
- Cybersecurity: Transformers help detect network intrusions and malicious activity by modeling normal versus suspicious behavior, as seen in tools like QRadar.
Final Thoughts
Transformers have reshaped the landscape of AI by offering a flexible, powerful approach to sequence modeling. While high costs and data demands are valid concerns, the transformative impact of this architecture across industries—from language and vision to biology and security—is undeniable.
Understanding how Transformers work isn’t just for researchers; it’s increasingly essential for developers, product teams, and business leaders seeking to harness AI’s full potential.
")


